MAE(MUXI APP ENGINE) 主要分为两个部分:
- 基础业务
- 集群管理
对应 Github 上的 specs Github 上为英文版本
因为历史原因,项目基本结构并不是 DDD
但是大部分分包也是比较清晰的,虽然并不指望有人维护,这也是代码里要更多考虑 自恢复/差错容忍/其他人为外部运维因素 的原因
部分设计参考阿里成熟的开源项目 kubevela
项目代码清晰,符合普遍的社区标准
但是目前还未开源…
此介绍文档还在不断更新,如果更新了设计,以及我想更新哈哈哈qwq
技术选用:
Mysql因为本项目大部分数据的数据模型都是关系模型,所以选用了较为熟悉的 RDBMysql,Gorm作为orm框架Redis本项目需要最基本的 业务层缓存 以及 轻量消息队列作为缓冲,所以选用了较为熟悉的 RedisClient-go管理集群是本项目核心部分,目前团队基本所有服务都部署与k3s(更轻量的 k8s,减少服务器负载) 管理的集群上,所以选用 client-go 作为项目与集群的交互的 k8s SDKGin为本项目的 Web 框架
重点:
- 关于集群管理
- 关于某些场景下一致性的讨论
基础业务
用户系统
最基本的用户系统,以及鉴权 接入团队 OAuth2.0 接口,设计实现 OAuth Interface,符合规范,便于接入其他的 OAuth 认证平台
黑名单在服务启动时从 Mysql 数据库 Fan-out 到 Redis 缓存,便于后期使用 黑名单部分作为 协程(goroutinue) 加快项目启动时初始化的速度 可以考虑将 Redis 部分做成布隆过滤器,但是项目目前使用人数较少,未启用
组织系统
用户可以成为相应组织的成员,组织是根据团队内的应用划分(application) 的 主要用途:
- 同时 application 也用于划分 k8s 集群上的 Namespace
- 用于隔离不同的 application 的资源
- 用于在不同操作时进行 RBAC 鉴权控制
服务管理(部署)
每一个服务都属于一个应用(因为基本都是微服务,以及一些单体小服务,都适用于服务的概念)
传统的部署方法:创建 NS(如果没有) -> 创建 Ingress(附带 SSL 相关资源) -> 创建 Deployment -> 创建 Service
这里将 Deployment 和 Service 聚合在一起,只给用户暴露一个 服务(Service) 的概念 还有一个 Ingress 路由的概念,其余与 k8s 交互及逻辑部分内部实现
用户可以 自定义模板(template) (通过 text/template 解析后,绑定到 k8s resource 的各个参数)用于生成部署在服务器上的资源
具有有默认模板,适用于大部分业务
并且将通用配置的统一出来,填表部署(填充必须字段)
子模块:
- 部署记录,也根据路由和服务分为两个部分 特定的 ID 记录用于 回滚 特定版本(集群粒度的控制),并且 实时(refresh status) 显示每个部署的服务在集群上的状态 至于为什么需要用户手动刷新或者刷新页面,减少服务器负载,如果什么都用最极致的,那肯定 websocket 了,但是太重了,也不需要 也可以 setInterval 1s 定时刷新
部署状态
我们都知道 k8s 的资源是需要创建的,其中 Ingress, Service, Namespce, Deployment 的创建结果都是会同步被 api-server 返回的,那么我们可以假设,如果他创建成功,那么他就是成功的了 事实上,如果我们忽略运维人为删除,那么这个状态就是可以保证的,将状态写入到数据库进行持久化 而 Deployment 下面的 RS, node 则较为复杂,下文也会讨论到
那么我们可以很方便的将部署状态分为两部分:创建时(api-server)状态和运行时(在集群上)状态
-
创建状态 这里主要考虑的是 Ingress, Namespace 的直接创建结果 如果还未触发第一阶段的回调(创建回调): 部署中 成功返回:部署成功 失败返回:部署失败
-
集群状态 从项目的角度来说,Ingress, Namespace 之外的概念应该是 Version, 这里就直接对应到 Service + Deployment 两个的状态,为了保证 Service 和 Deployment specs 的一致,不遗漏修改信息,我们选择 diff 一下然后 update/create 而这两个的创建时状态和上面一样 这里主要涉及的是之后的状态:Pending, Healthy, Failed
最后,每一步的部署,都会对应一个 RecordID,每个 RecordID 可以对应到对应的 Log Records 来让用户观察到其中部署的细节,像其他 CI 的 Log 一样的效果。 当然这里会考虑到一瞬间大量日志挤爆 Mysql 的情况,这种情况下我们可以加入 MQ 来缓冲一下,使流速均匀。
服务器、集群
-
服务器 因为团队所需的服务器也不是很少,因此需要单一的服务器记录系统 业务需要记录服务器的各种配置信息以及过期信息 到期前若干天触发过期提示
设计是:用户创建 RAM 用户(阿里云概念,可以是其他信息) -> RAM 自动导入服务器信息
抽象 ECS Interface 用于从服务商导入服务器
-
集群
目前采用的方式是使用集群内 ServiceAccount 的 Token + CA 证书,用于访问集群内的服务(一个集群一个)
关于集群部分的权限控制需要在集群上改动其权限,从 MAE 中剥离开来,这也是初始化集群的时候应该做的(目前手动,可以考虑 bash 脚本自动 scp 到本地然后走 api 上传)
流水线(CI pipeline)
关于团队自建的 Drone CI ,需要将 Build 部分接入到 基础业务 中 设计 CI Interface,用于兼容不同 CI 的 SDK 主要用于将服务的部署部分都集成到一起(用户通过 push gitea 的 tag 触发 drone ci 的 trigger,最后 MAE 一键部署)
通知系统
具体的通知分发业务后迁移至 MUMS 项目 主要涉及 服务器到期,服务部署状态提示 等
指标(metrics)
只做服务内各指标监控 暴露出用于监控该服务的内部信息,暴露到 Prometheus,然后接入 Grafana 监控整个服务情况 Tracing 部分正在完善中,可以更好的掌握服务性能等
集群管理(Cluster Management)
概览
MKE(MUXI K8s Engine) 是独立于 MAE 存在的与 k8s api server 交互的,自己封装 libary(大概算是)
-
MKE with client-go
MKE 内嵌于 MAE 中的部分 通过 k8s 官方的 SDK client-go 与目标 集群上的 api-server 交互 这一部分主要这几了最基本的(也是业务需要的) 创建,更新,删除 等等功能
-
MKE CRD
搭配 MAE 使用的 Custom Resource 是一个 Controller 的角色,辅助 MAE 进行整个集群上部署情况的整理
因为单纯使用 clinet-go 与集群交互对于一些监控状态操作不是那么直接(如:Deployment 的具体状态,同时涉及 Deployment 与 ReplicaSet)
并且在测试场景遇到了一些 BUG(已经忘了是什么了,好像是在 服务重启时 会 重复触发 事件) 于是直接选择了最开始就想的集群 CRD 方案,让这一部分作为 CRD 运行在各个集群上去帮助我们得知 Deployemnt 的状态,反馈回来
还有一个原因就是,我们的 MAE 与 集群 交互是走公网的,因为可能会与不同的集群不在同一个地域,所以也要尽可能的减少与集群间的网络流量,并且学生机性能并不好,尤其要减少单个服务器的处理任务(均摊)
详细资源
接下来是根据 k8s 中我们需要用到的具体的资源
Namespace
Resource relations: Namespace <—> Cluster <—> Application
Namespace 作为 K8s 中最直接的隔离资源的概念,非常适合对应到我们业务中的 Application
-
新的 Application
先根据 Application 的 name(符合 RFC 规定的) 在所有的集群上创建 Namespace
-
新的 Cluster
根据所有存在的 Application 在新的集群上创建 Namespace
这样就保证了所有的 Application 在不同集群上的迁移部署等等(因为这里的集群对所有的服务都是可用的,所以是所有的集群,如果涉及到其他粒度的控制问题,则需要再加详细的控制逻辑)
Ingress
Resource relations: Different env(product/test) <—> Namespaces <—> Service <—> Ingress
Ingress 作为内部服务暴露到集群与外界交互的一部分,需要用户自定义每个 Route 的细节,并且可以引入 SSL
-
创建流程:
新的 Ingress 资源 -> 在目标集群上 Apply -> 如果有错误,直接 Callback
-
如何收集需要部署的目标集群
因为这里的集群分为 Test 和 Product 两种,每次的部署需要同时考虑这两种 对应关系为: ns -> services, ns -> ingresses, service -> clusters => ingresses -> clusters
同时,所有的 Ingress 资源在集群中由 name(version) 来区分 Ingress 的 更新,创建,新版本发布,在不同的 版本之间是分开的,但是在不同的集群(生产/测试)上是可以不同的
Service + Deployment => version
讲 K8s 中的 Service 和 Deployment 组合在一起,形成本项目中的 版本(version) 的概念,也就是向用户暴露的概念,用户的所有操作都是对 version 的操作,其中的信息也是直接编写对应 version 的 service template
-
状态
分为两个部分:
- 部署(deploying)到集群上的状态
- 已经在集群上的状态 Pending,Success 或者 Failed 并且把这些日志集成到对应部署记录的日志中,通过特定的部署记录访问相关的部署日志 如上述 部署状态 所述
-
回滚
对于每一条 DeployRecord, 都可以回滚到相应的版本状态 关于其他的 metadata, 统一 JSON 序列化,每次使用时再反序列化
-
流程
关系:一个版本对应多个资源对应多个集群 one version -> multiple resources –> multiple clusters 对应到集群上的关系:
new deployment -> replicaset(s) -> pod(s)
new version -> apply on target clusters(service && deployment) -> callback
-
service
因为 service 也是只涉及一个单独的创建资源过程,所以这里采用的方法是直接 callback 触发相关流程,也不需要重试等等
-
deployment
之前的设计: 通过 go-client 内置的一系列
watcher那一套去接收目标服务器的事件,再处理goto deploymentStatusWatcher -> replicasetsWacher -> podWacher -> callback
现在的设计: 对于创建资源状态阶段 是可以直接 callback 的 对于在集群上的具体状态是要通过 deploymentWatcher 返回来的状态更新
-
具有默认模板给用户使用
一些讨论
Callback
很明显,各种因素(主要是响应时间),导致了这里的所有与 集群 的交互过程基本都是异步的
所以这里使用了 Callback 机制来完成所有的异步回调,更新状态机状态
场景举例:
-
创建资源 只需要用 MKE 封装的 apply 方法进行创建资源操作,将结果处理函数 这样将 MKE 与 MAE 完全解耦,使得 MAE 某一个资源的后续操作完全自由控制,MKE 只负责回调 具体操作是再次封装 MKE 的各种方法,放在
/service中,作为cluster的一种service调用如图:
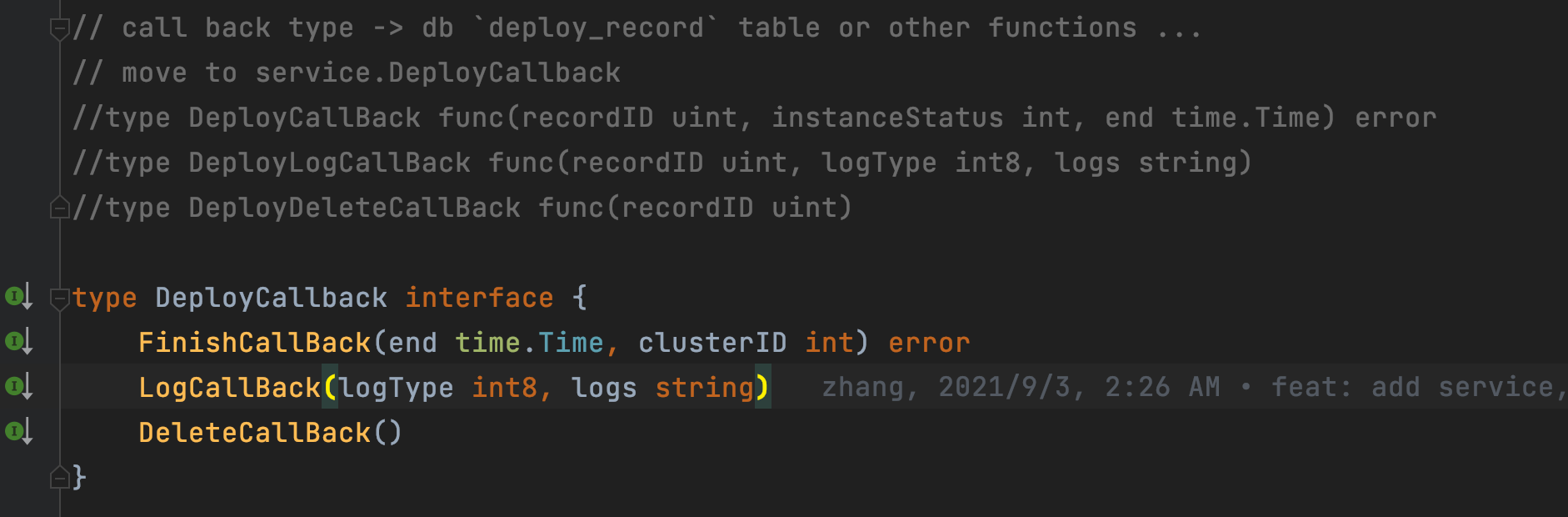
CallBack 的 Interface 设计 具有三个主要的函数,分别对应 完成、日志、删除 并不对应 成功/失败 具体逻辑由 service 决定,service 只保证一个服务会成功的写入日志 Log,并且成功的返回部署的状态,并且会在必要的时刻删除该记录(当然这里是软删除)标记不可用
一致性
持久化
作为保障一致性最有效的手段就是持久化 每一部分关于资源的一些状态,都需要持久化,并且需要一些策略来保证每个事件对每个状态机的影响,同时需要保证每次交互的 幂等性 这里持久化的内容规定为:所有资源的状态,每次更新都需要同步,DB 部分交给 MySQL 来完成,上层部分通过各个资源的状态机来完成,以及最重要的,每一次更新资源状态的 DeployRecords 通过最新的 DeployRecords, MAE 可以正确的获取到当前达成的状态,如果产生某些状态缺失,则会立即更新,并且如果有多个事件到达,只会更新最新的事件,并且会更新所有以前未完成的状态
一致性
我们的一致性模型是无主的,可以有若干个 MAE 部署在若干地方 只要保证每个请求打到任意一个节点,那么他的状态就是全局可见的,因此不会有冲突,如果这个节点挂掉,那么他的状态也一定是没有被执行的,那么一定会有新的事件顶替掉这个旧事件 当然我们理想的场景是,有限个 MAE, 每个集群一个 deployment operater 所以我们需要更多的考虑,当旧 MAE 挂掉之后,新的 MAE 起来的时候,看到的状态是否是一致 事实上,在我们实现的模型中,因为 Goroutinue 是无状态的,所以会丢失创建资源的最终状态,或者超时回调,但是这个本身概率就是很小的(api-server 的访问非常迅速) 关于 deployment-operater, 可以将最新的 状态信息发送到目的 MAE 实例,如果没有收到 OK 的 response,那么就认为是无效的,需要重新发送,这里可以加入 二进制指数退避算法 重试 这样,最终的状态一定是不会冲突的,达成了我们可以容忍的弱一致性
在以上两点的基础上,容错机制也就体现出来了,因为总会有更新的事件去更新上一个挂掉的实例未完成的事件
为什么把 deployment-operater 剥离出来
上文讨论过具体的思考 同时也是为了方便后面更多的 CRD 资源出现
配套组件
MUMS
MUMS(Muxi Unify Message System)
用于统一目前可用的 飞书、钉钉 等第三方消息推送服务 用于推送到团队此基础平台的各种通知消息
目前已有:feishu-bot 用于推送 ci 的构建结果
… TO BE CONTINUE