主要讲述ES 7.x 版本的东西,附带同样基于Luence并且很火的Solar和ES的对比
1. Luence
是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎
Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
简而言之:Lucene是apache下的一个开源的全文检索引擎工具包。
更多有关Luence:
https://tool.oschina.net/apidocs/apidoc?api=lucene-3.6.0
https://lucene.apache.org/core/
Luence的全文索引
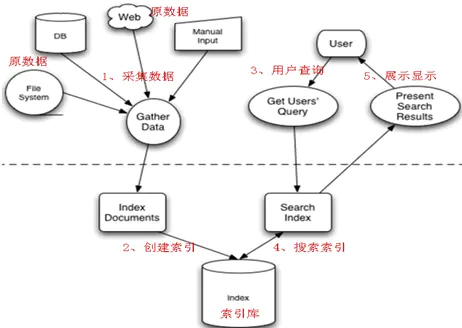
2. Solar & ES
2.1 Solar
Solr 作为 Apache 基金会的顶级项目,技术成熟而且用户量巨大。
在ES发布之前搜索引擎就是Solar的天下
Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。
2.2 ES
通过简单的 RESTful API 来隐藏Lucene的复杂性,从而让全文搜索变得简单。
2.3 比较
1.ES开箱即用
2.ES自带分布式协调管理
3.Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式
4.Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用
ES建立索引快(即查询慢),即实时性查询快
3. ES 7.x
3.1 ES 的好朋友们
众所周知,大家都喜欢看有UI的东西,ES也具有很完备的WebUI,并且在积极的维护着
ELK-Stack(elastic stack)
Logstash:数据收集,处理和储存
Elasticsearch:检索和分析
Kibana:可视化
Beats:轻量级(资源高效,无依赖性,小型)的日志发送程序。收集数据 –> Logstash (建立在名为libbeat的Go框架之上
-
elasticsearch head
elasticsearch head 算是一个轻量级的管理器
7.0版本支持SQL(X-Pack)
3.2 ES 7.x
3.2.1 前情提要(上次所讲到的,和一些没有讲到的但是是基础的)
ES是一个分布式搜索引擎,底层使用Lucene来实现其核心搜索功能,所使用的是NoSQL(not only SQL)
核心:全文索引
全文索引
更适用于非结构化数据 (格式和长度不固定的数据),传统数据库查询效率很低
倒排索引
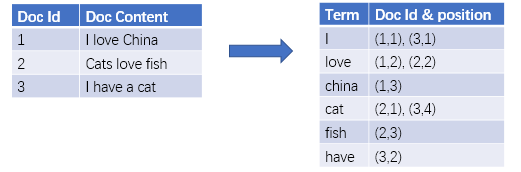
倒排索引会先对文档进行分析将其拆分成单个Term, 并存储包含该Term的文档id
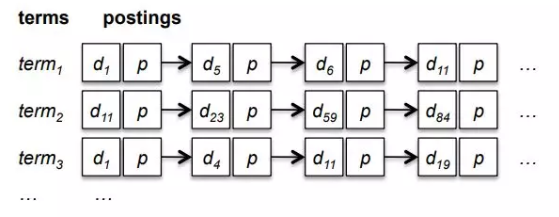
这样的倒排索引建立起来会导致索引的大小迅速膨胀,对此引入了一个特殊的数据结构叫FST(有限状态转换器) ES使用了索引帧(Frame of Reference)技术压缩posting list
然后是ES的基本概念:
-
Index: 索引
集合,类比DB
-
Type:
“_doc”
最近版本取消自定义
-
Document: 文档
记录
-
Field:字段
某一属性
库(database)索引(index)表(table)类型(type)行(row)文档(doc)列(column)字段(field)
类型
core datatypes: string:text/keyword numeric:long, integer……….
complex datatypes
gro datatypes
specialised datatypes: ip, rank feature
https://www.elastic.co/guide/en/elasticsearch/reference/7.7/mapping-types.html
-
mapping(索引模板):
两个创建途径:
a. 当放入的数据不属于当前Type中任何一个的时候会自动创建
b.通过
settingsmappings来创建通过mapping和setting可以设置很多属性:
store: 是否存储 analyzer: 分词器,默认是standard analyzer boost: 增加该字段的权重 format: 设置输出格式(日期) https://www.elastic.co/guide/en/elasticsearch/reference/7.7/mapping-params.html -
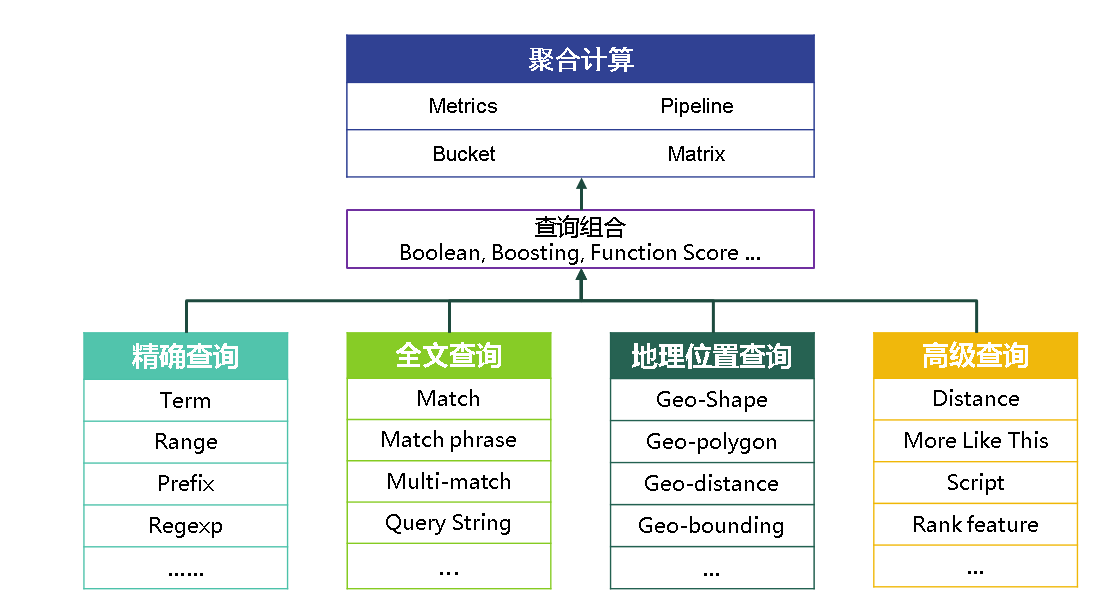
聚合:
类比pipiline
-
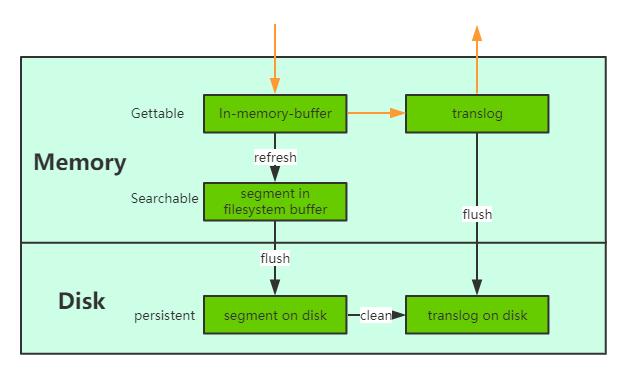
refresh:
刷新时间间隔
default:1s
-
translog:
当一个文档写入Lucence后是存储在内存中的,即使执行了refresh操作仍然是在文件系统缓存中,如果此时服务器宕机,那么这部分数据将会丢失。为此ES增加了translog, 当进行文档写操作时会先将文档写入Lucene,然后写入一份到translog,写入translog是落盘的。可以设置成异步存储。
-
flush:
每30分钟或当translog达到一定大小,ES会触发一次flush操作,此时ES会先执行refresh操作将buffer中的数据生成segment,然后调用lucene的commit方法将所有内存中的segment fsync到磁盘。此时lucene中的数据就完成了持久化。
-
fliter:
过滤
filter语句采用了Roaring Bitmap技术来缓存搜索结果,保证高频filter查询速度的同时降低存储空间消耗。
-
score:
默认情况下,Elasticsearch按相关性得分对匹配的搜索结果进行排序,该得分衡量每个文档与查询的匹配程度。
-
分片与备份:
分布式设计:为了支持对海量数据的存储和查询,Elasticsearch引入分片的概念,一个索引被分成多个分片,每个分片可以有一个主分片和多个副本分片,每个分片副本都是一个具有完整功能的lucene实例,可以独立进行存储和搜索。分片可以分配在不同的节点上,同一个分片的不同副本不能分配在相同的节点上。
Elasticsearch的早期版本默认为每个索引创建五个分片。从7.0.0开始,默认值为每个索引一个分片。
在进行读写操作时,ES会先计算出文档要所在或要分配到的分片,再从集群元数据中找出对应主分片的位置
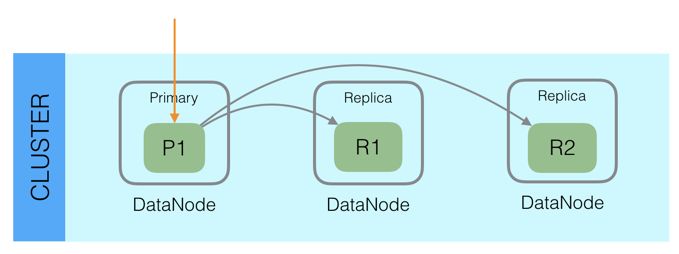
更多的基本概念:https://www.elastic.co/guide/en/elasticsearch/reference/7.7/glossary.html
3.3 ES 使用
3.3.1 插件
ES插件有很多,这里只介绍一个。
更多的时候我们需要通过聚合不同的插件来达到我们的目的,这也是ES极其强大的原因之一
- ik
- pinyin
ik是一款用于es的中文分词器插件
pinyin是一款用于es拼音形式的插件
3.3.2 Restful格式下的使用
-
写入
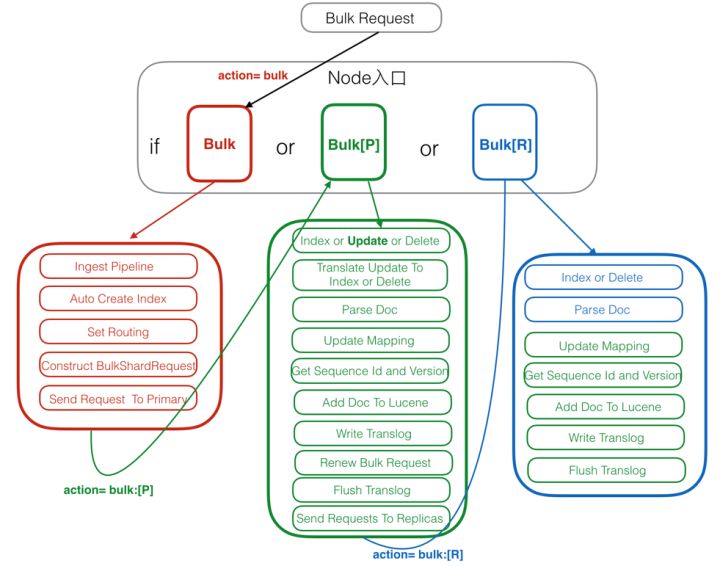
https://cloud.tencent.com/developer/article/1531723 -
查询
GET /s1/_search
{
"query": {
"match_all": {}
}
}
#手动创建settings与mappings
#不可覆盖
PUT /s1/#_settings
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"first": {"type": "text", "analyzer": "ik_max_word"},
"last": {"type": "text", "store": false}
}
}
}
#_bulk 批量操作
#自定义添加/修改
PUT /e1/word/1
{
"first": "wo",
"next": "ww"
}
POST /e1/word/
{
"f": "q",
"n": "w"
}
PUT /s1/_bulk
{"index":{"_id":"1"}}
{"first": "世界","last": "中国"}
{"index":{"_id":"2"}}
{"first": "华师","last": "木犀"}
{"index":{"_id":"3"}}
{"first": "我爱中国","last": "中国"}
{"index":{"_id":"4"}}
{"first": "世界","last": "美国"}
{"index":{"_id":"5"}}
{"first": "世界","last": "英国"}
{"index":{"_id":"6"}}
{"first": "我爱中国","last": "中国","ex":"我"}
#获取配置
GET /e1/_settings
GET /e2/_settings
GET /e1/_mapping
#所有的类型设置
GET _all/_settings
#获取
GET /e1/word/2?_source=n
# 通过_version和version_type=external 进行版本控制
#基本查询
GET /e1/_search?q=first:wo
#ik 全文查询match
GET /s1/_search
{
"version": true,
"from": 0,
"size": 2,
"_source": {
"includes": "fir*",
"excludes": "w"
},
"query": {
"match": {
"first": "我"
}
}
}
#query:"我"
#fields:["first","last"]
#range: "fields":"from":,"to":
#sort
#wildcard: 可用"*/?"
#fuzzy: 模糊查询
#filter: 过滤上下文
# ik + pinyin
GET /test8/_settings
GET /test8/_mapping
GET /_analyze
{
"analyzer":"pinyin",
"text":"我爱中华人民共和国"
}
PUT /test8/_doc/3
{
"content": "我爱华师"
}
PUT /test8/_doc/4
{
"content": "中国武汉"
}
PUT /test8/_doc/5
{
"content": "武汉在中国"
}
GET /test8/_search
{
"query": {
"match": {
"content": {
"query": "zg"
}
}
}
}
如何自制分析器:
https://www.elastic.co/guide/en/elasticsearch/reference/7.7/analysis-custom-analyzer.html
3.4 ES 与 Go
ES虽然很早就出现了,但是最先写Go语言使用ES的一些接口框架的并不是官方,所以事实上另一个第三方包更火一点(星星数),并且作者也在积极的维护,功能完备
这两个包分别是 olivere/elastic 和 elastic/go-elasticsearch
这里主要介绍olivere/elastic这个第三方包具体使用情况和grom挺相似的
一些示例代码
算了,直接看官方的吧:https://olivere.github.io/elastic/
参考链接
https://www.elastic.co/cn/logstash
https://www.cnblogs.com/blueskyli/p/8326229.html
https://cloud.tencent.com/developer/article/1543565
https://zhuanlan.zhihu.com/p/137574234
https://www.cnblogs.com/LQBlog/p/10449637.html