本文主要科普一下当前比较热门的分布式 主要涉及 分布式基本概念,共识性算法 其实说是科普,但是听完你就可以和绝大部分半调子人聊的有来有回了 ~ 和别人吹水的时候说:诶,你这个考虑分布式了么,是不是很牛的样子? 虽然我不这么觉得,但是考虑分布式是有必要的 hhh
分布式
Why we need distribution? (drivens)
开始之前我们先来讨论一下我们为什么分布式
分享结束之后再看一遍这些问题
-
性能 如何做到简单的增加服务器就使性能增强(像 GFS 的假设) 这时候我们需要设计一个架构来将这种能力推进下去
-
容错 比如你的两台服务器,挂了一台 如何做到继续可用(当然故障多了就不能用了) 1000台呢(会被无限放大)
-
物理分布 地球这么大,你的数据中心一定会分布到不同的地方
-
安全性 你这个代码他不安全啊,分布式可以做到某一部分是这个代码,并且挂掉并无影响
Distribution
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。
其实分布式很简单,就是多台机子,部署在不同的地方,通过网络通信(大部分都是 RPC)协作
但是我们需要很多额外的策略
因为网络是不稳定的,物理上也是不稳定的,节点(机器)是不稳定的
…
这些都要考虑到一个分布式系统的设计上
一些概念与指标
- 一致性
这个大概就是最重要的了,分布式系统的行为要表现出一致性
- 强一致性 就是说如果 A 在 B 之前请求(避免语义问题,这里是达到服务器),那么 B 得到的结果一定是 A 之后的状态。
- 弱一致性 弱一致性其实是很拥有的 比如当副本很远的时候可以采取最近节点通信的方式,你可能不会 get 到最新的 key,但是绝大部分场景都是对的,并且有良好的速度,以及低成本(相对强一致性)
- 可用性
在特定的错误类型下,系统仍然能够正常运行,仍然可以像没有出现错误一样,为你提供完整的服务。
- 容错
- 自恢复 一个节点 recover 之后需要自恢复,
- 拓展性(性能) 就是上面说的,一样
指标
-
CAP 我们会更倾向于用 CAP 去划分一个分布式系统
CAP 问题就是在出现分区问题的时候,是选择一致性还是可用性
-
一致性 同上
-
可用性 可用性一般有两个意义:
- 一个是普遍意义上的可用性,即容错和自恢复
- 另外一个是指对于每一次请求,都能够得到一个及时的、非错的响应,但是其实是不保证请求的结果是基于最新写入的数据。 CAP 理论指的是后一个,这也是为什么大部分分布式系统都是 CP 或者 AP
但其实 DDIA 中并不建议使用这玩意,但是现在大家说的还都是这个吧 hhhh 据说更精确的是 Consistency, Availability, and Convergence https://apps.cs.utexas.edu/tech_reports/reports/tr/TR-2036.pdf 但是咱也没看这篇呢,咱也不细说
-
分区容错性 基本指的是网络层面被划成若干个区情况下的容错性 为了避免混乱,说明一下其实这个玩意,就是容错,我们一般不会把他与正常的故障分开讨论,但是这里是 CAP 的 P
这个 CAP 其实也经过了漫长的演变
ch: https://www.infoq.cn/article/cap-twelve-years-later-how-the-rules-have-changed/ ori: https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed/
-
-
FLP FLP 不可能原理
《Impossibility of Distributed Consensus with One Faulty Process》指出:在网络可靠,但允许节点失效(即便只有一个)的最小化异步模型系统中,不存在一个可以解决一致性问题的确定性共识算法
注意这里是异步的(这个其实在这次分享里不是很重要,在这里我们主要讨论同步调用,但是是分布式基本概念)
-
BASE BASE 理论主要是针对分布式场景下数据库 应用可以采用适合的方式达到最终一致性(Eventual Consitency)。
- 基本可用 允许损失部分可用性,即保证核心可用。 降级服务
- 软状态 允许中间状态 扩大来说就是允许副本之间时延
- 最终一致性 经过一段时间一定是一致的状态
很简单很简单,我们看看共识性算法,就流程来说也很简单~
共识性算法
共识性算法算是分布式中最重要的一部分,在这一部分,我们可以对上面很多挑战做出解答 当我们讨论分布式的时候,应该把他和共识性算法分开来看待 当然他也很复杂(实现层面) 这里就是简单的让大家看一下他们是如何设计的(流程上) 当然不会涉及到太多的具体的 specs
通常只在每个分区内维持顺序,这意味着它们不能提供跨分区的一致性保证(例如,一致性快照,外键引用)。 跨所有分区的全序是可能的,但需要额外的协调
主要是 Paxos 和 Raft,其他
我能听到的 VSR 和 Zab
(Basic-)Paxos
我感觉时间可能会有点长,而且会和 Raft 搞混?所以还是简洁一下就略过吧 hhh
反正绝对没人会让你实现这个
角色:
- client 客户端
- acceptor/voters 决议
- proposer 提议
- learner 就是记录的
这个玩意主要分为两个阶段,一个是准备决议,一个是批准
Client Proposer Acceptor Learner
| | | | | | |
X-------->| | | | | | Request
| X--------->|->|->| | | Prepare(1)
| |<---------X--X--X | | Promise(1,{Va,Vb,Vc})
| X--------->|->|->| | | Accept!(1,V)
| |<---------X--X--X------>|->| Accepted(1,V)
|<---------------------------------X--X Response
| | | | | | |
但是这个其实有个缺陷,就是作为理论研究挺好的,但是实际场景就有点尴尬(流量过多),所以有了 Mutil-Paxos。
Raft
(其实这个才是最初分享的重点,但是我觉得还是分享一个分布式的思想比较有意义,Raft 学完就忘)
基本就是解析 raft-extended c1 - c5(c7) 不,我不配,而且不太适合做分享,太细致了
这个出现就是说,因为 Paxos 太难懂了 就但是这个其实也没那么简单
他主要分为几个部分:
- Leader 选举(leader election) 随机时间
- 日志(log replication)
- 安全(safety) 这里的安全主要是指如何安全的保证日志的一致性
这里我们只介绍一下 Leader 选举和最基本的如何保证一致性(没那么多复杂状态)好了
现实中是如何设计分布式的
这个涉及的太多了,等我学完再说吧
就大概那样吧,不同策略结合,现场说吧
数据中心,分片(Map-Reduce)
不断屏蔽下一层设计(以 kv-db 为例:client -> data-center(k8s/swarm multi-master) -> db-nodes(raft …) -> storage(gfs/hdfs/megastore …) -> … )
当然不同的设计是不一样的
多主之间的一致性:
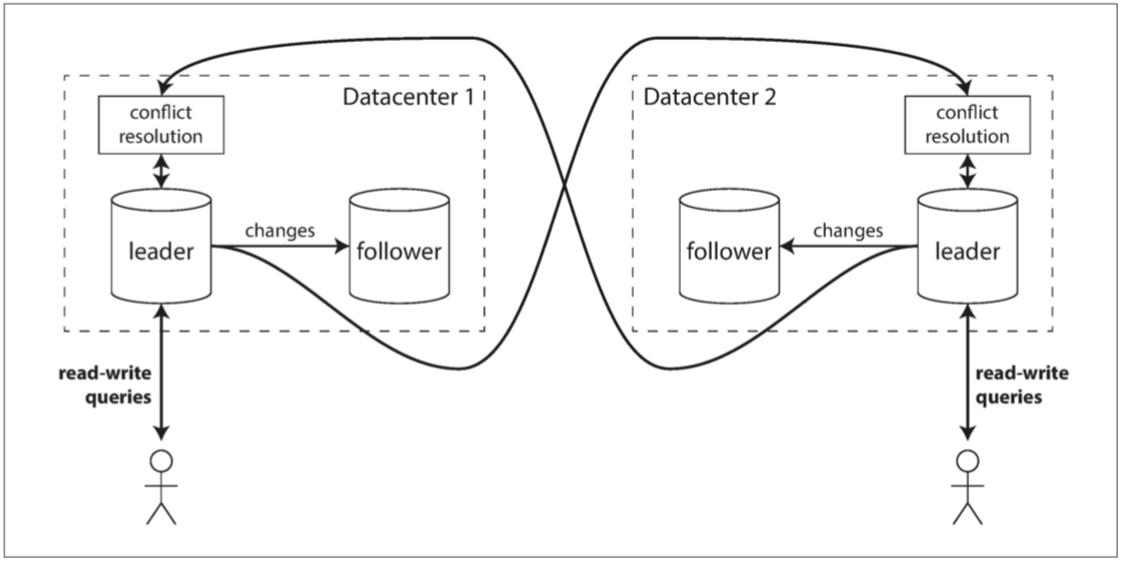
很复杂咯,但是主要问题就是: 复制 + 解决冲突
拓扑复制:
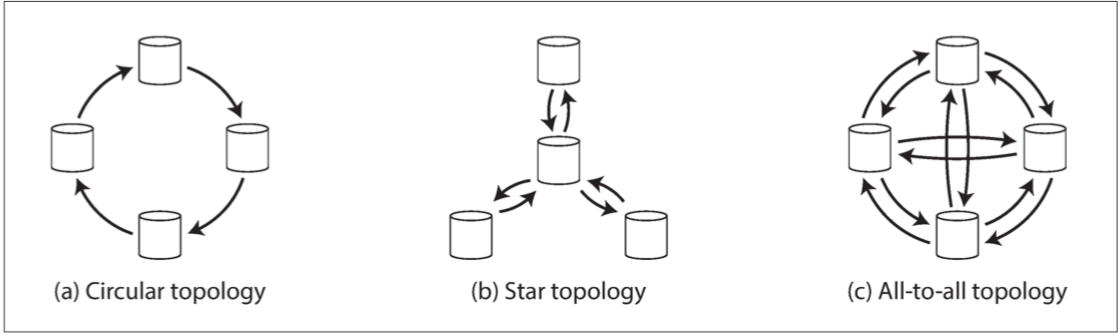
主要就是处理写入冲突,毕竟是给大家分享,这里举个大家都听过的最简单的方法:UUID 最后写入胜利(LWW)
其他:Conflict-free replicated datatypes、Mergeable persistent data structures、Operational transformation 都需要具体实现
你们可能会见到的:两阶段提交(2PC)
当然这些还只是入门,分布式坑很大,很值得思考,很值得去寻找解决方案
refs:
https://en.wikipedia.org/wiki/Paxos_(computer_science) https://stackoverflow.com/questions/25230005/leader-address-location-in-raft https://vonng.gitbooks.io/ddia-cn